
作者:科学中国人 发布时间:2024-04-15
更高清图像的精确理解、更高质量的训练数据、更强的图像解析推理能力,还能结合图像推理和生成,香港中文大学终身教授贾佳亚团队提出的这款多模态模型Mini-Gemini堪称绝绝子,相当于开源社区的GPT4+DALLE3的王炸组合!
Mini-Gemini还提供了2B小杯到34B的超大杯,最强模型在多个指标上相比Google Gemini Pro甚至GPT-4V都不遑多让。目前,Mini-Gemini从代码、模型到数据已全部开源,登上了PaperWithCode热榜。
Mini-Gemini线上Demo也已发布,Mini-Gemini Demo放出后受到广大网友关注,一番“品尝”后,他们认为Mini-Gemini跟商业模型差不了多少!

目前,绝大多数多模态模型仅支持低分辨率图像输入和文字输出,而在实际场景中,许多任务都需要对高清图像进行解析,并用图像的形式进行展现。
Mini-Gemini不仅能够根据图片对做面包的过程进行手把手教学,也能够准确将不同电脑品种根据图片中的各种参数进行对比。网友表示:妈妈再也不用担心我的生活了。
更重要的是,Mini-Gemini在保留超强的图像理解和推理能力的同时,还解锁了图像的生成能力,就如同ChatGPT和生成模型的结合。
案例分析
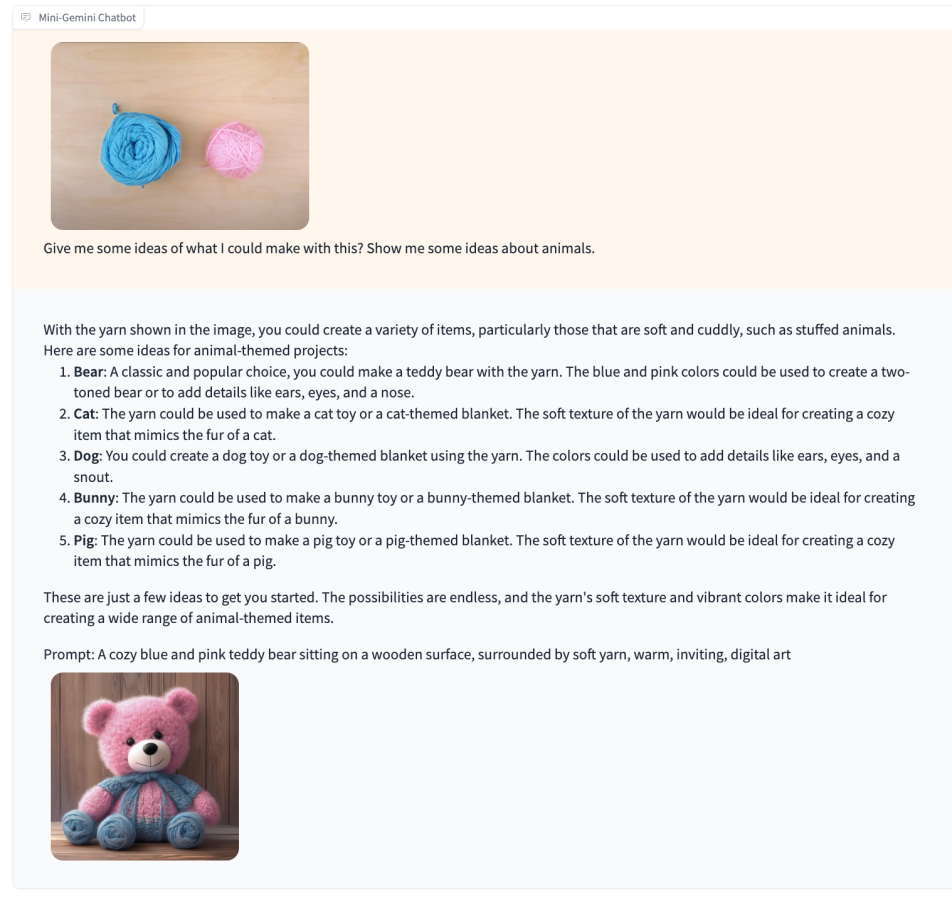
当我们把相似的输入给到Mini-Gemini,可以发现,Mini-Gemini也可以识别出图片中的元素,并且合理地建议,同时生成了一只对应的毛线小熊。
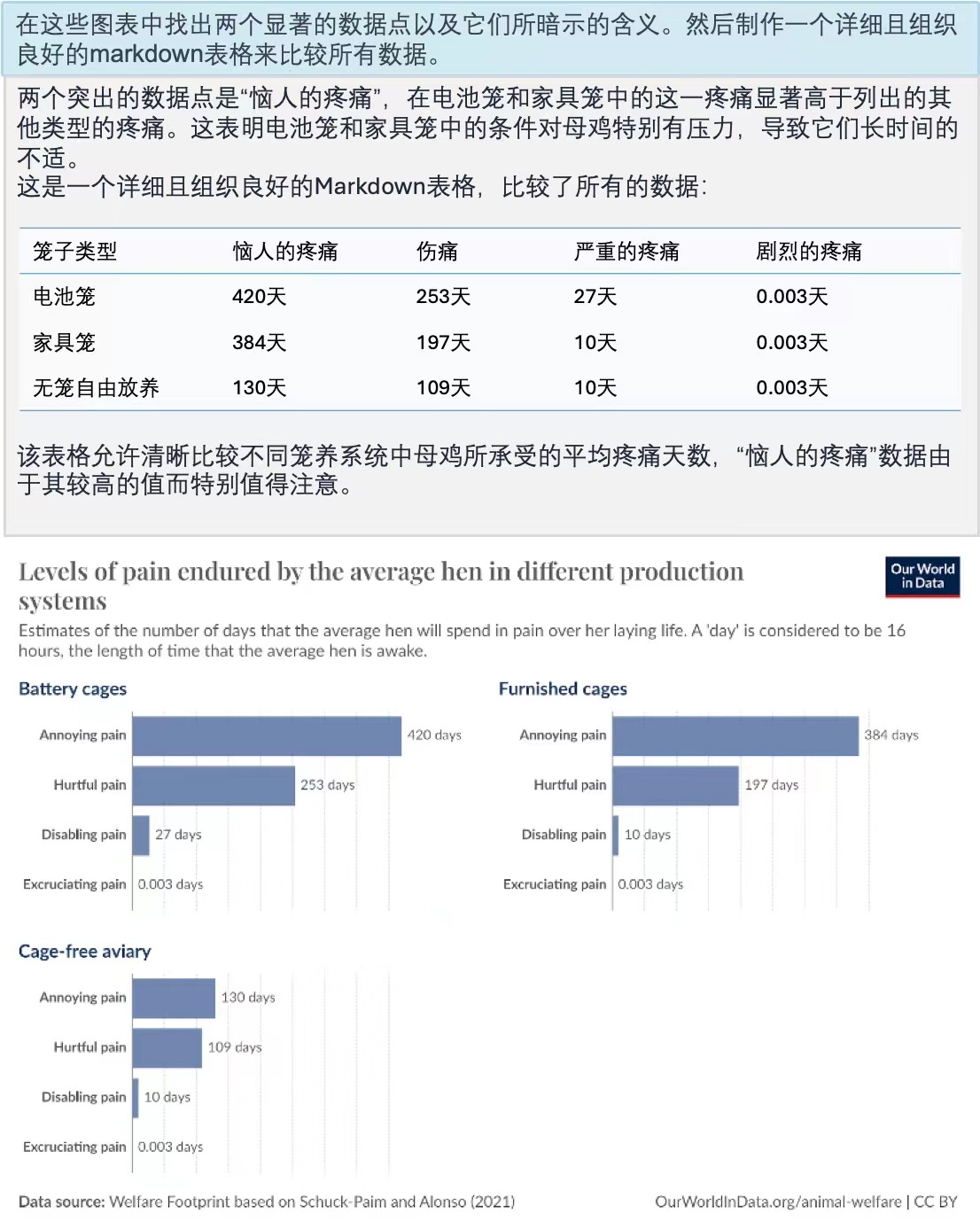
高清复杂的多图表理解和归纳对Mini-Gemini来说也是小菜一碟,Mini-Gemini直接秒变打工人效率提升的超级外挂。
技术细节
- 资讯
-
-
《科学中国人》杂志社新闻记者证人员公示
根据《国家新闻出版署关于开展2025年度新闻记者证核验工作的通知》...
-
中国科技新闻学会理事长徐延豪一行赴《科学中国人》杂志社调研指导
2025年12月8日上午,中国科技新闻学会理事长徐延豪带领学会秘书处有关同...
-
2025年中国科技传播论坛在京召开
11月24日,中国科技新闻学会主办的2025年中国科技传播论坛在京召开...
-
薪火十年,益心同行 | 北京白求恩公益基金会十周年纪念活动温暖绽放
八十六载精神传承,十周年初心不改。2025年11月12日,时值伟大的国...
-
《中国逻辑学大辞典(人物卷)》出版签约仪式在京举行
2月28日上午,《中国逻辑学大辞典(人物卷)》(原名《中国逻辑学家...
-
2024年中国科技传播论坛暨中国科技新闻学会第十七次学术年会在京召开
11月24日,中国科技新闻学会主办的2024年中国科技传播论坛暨中国科技新...
-
《科学中国人》杂志社新闻记者证人员公示

